SQLite 数据库从入门到精通
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
001 了解一下 SQLite 数据库 SQLite 是一个轻量级的嵌入式关系型数据库,它非常适合嵌入式应用和小型项目。 零配置:与传统的数据库系统(如 MySQL、PostgreSQL)不同,SQLite 不需要安装和配置任何数据库服务器,而是将整个数据库存储在一个单一的文件中,直接通过文件来存储和读取数据。 .db 或 .sqlite 文件中。SQLite 是一个以文件为基础的数据库引擎。每个数据库都是一个普通的磁盘文件,所有的数据和结构都存储在这个文件中。 .db:这只是 SQLite 数据库文件的常见扩展名。很多时候,这个扩展名是为了让文件看起来像一个通用的数据库文件,或者是根据开发人员的习惯命名。 .sqlite:这是 SQLite 数据库的另一种常见扩展名,通常用于强调该文件是一个 SQLite 数据库。也可以用 自包含:SQLite 是一个纯 C 实现的数据库引擎,所有的功能都可以在一个独立的文件中运行,因此非常适合嵌入式系统。 B-tree 存储:SQLite 使用 B-tree 结构来存储数据,使得数据库查询高效。B-tree 是一种自平衡的数据结构,适用于高效查找、插入和删除。 支持 SQL 语法:SQLite 支持标准的 SQL 语法,包括查询、插入、删除、更新等常用操作。 SQL 支持:SQLite 完全支持 SQL 标准,包含了大部分常用的 SQL 功能(如 JOIN、子查询、事务等)。
SQLite 数据库 是由 D. Richard Hipp 开发的,他是 SQLite 的创始人和主要维护者。SQLite 是一个开源项目,开发者通过它提供的 C 语言库来实现数据库功能。SQLite 数据库本身是一个独立的、嵌入式的数据库引擎,主要面向需要轻量级、无需独立数据库服务器的应用程序。 SQLite 数据库引擎是开源的,因此它本身并不直接通过销售许可或使用费来盈利。然而,SQLite 的开发和维护有一些间接的盈利来源和商业模式。 SQLite 的核心代码是 开源 的,并且遵循 公有领域许可(Public Domain License),这意味着任何人都可以自由地使用、修改和分发 SQLite 的代码,而不需要支付费用或获得授权。由于它是公有领域(Public Domain),SQLite 的核心代码没有任何版权或许可证费用要求。 咨询和技术支持:对于需要高质量支持或对数据库有特殊要求的企业,SQLite 的开发团队或第三方公司提供定制的技术支持和咨询服务。 定制开发:一些公司可能需要定制版本的 SQLite,或者需要额外的功能和优化,SQLite 的开发者可以为这些公司提供定制开发服务。 企业级解决方案:尽管 SQLite 是轻量级的,仍然有企业使用 SQLite 作为嵌入式数据库。对于这些公司,提供额外的企业级支持和优化服务可能是 SQLite 开发者的盈利来源。 DB Browser for SQLite 是由 社区开发者 维护的开源工具,它旨在为 SQLite 提供一个 图形化的界面,使用户能够方便地浏览、管理和编辑 SQLite 数据库。是由一群志愿开发者贡献代码来提供图形化支持。DB Browser for SQLite 使用广泛,特别是对于那些不想在命令行中操作 SQLite 的用户。
003 SQLite 数据库与Python 标准库中的 sqlite3 模块 sqlite3是一个 Python 的数据库接口模块,它为 Python 程序员提供了对 SQLite 数据库 的访问和操作能力。sqlite3 模块是通过 C 语言编写的,作为 Python 标准库的一部分,封装了对 SQLite 数据库引擎的访问。
Python SQLite 数据库源码:用 C 语言实现,负责处理所有底层数据库的操作和逻辑。 Python |
说明:
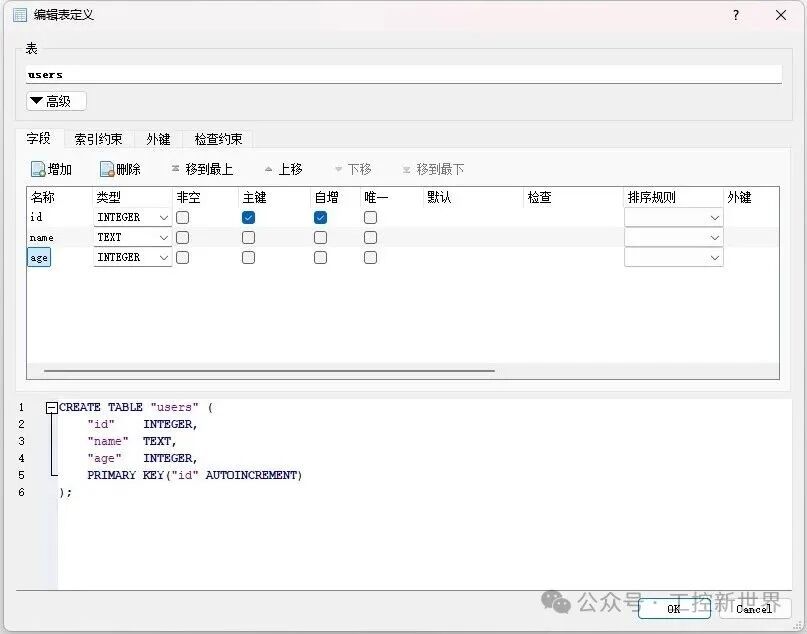
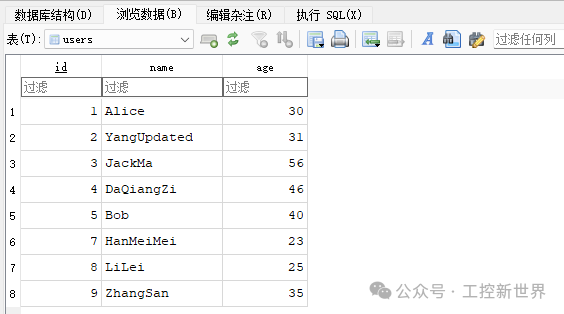
id 是主键,自增生成。
created_at 默认是当前时间,每插一条记录自动写入。
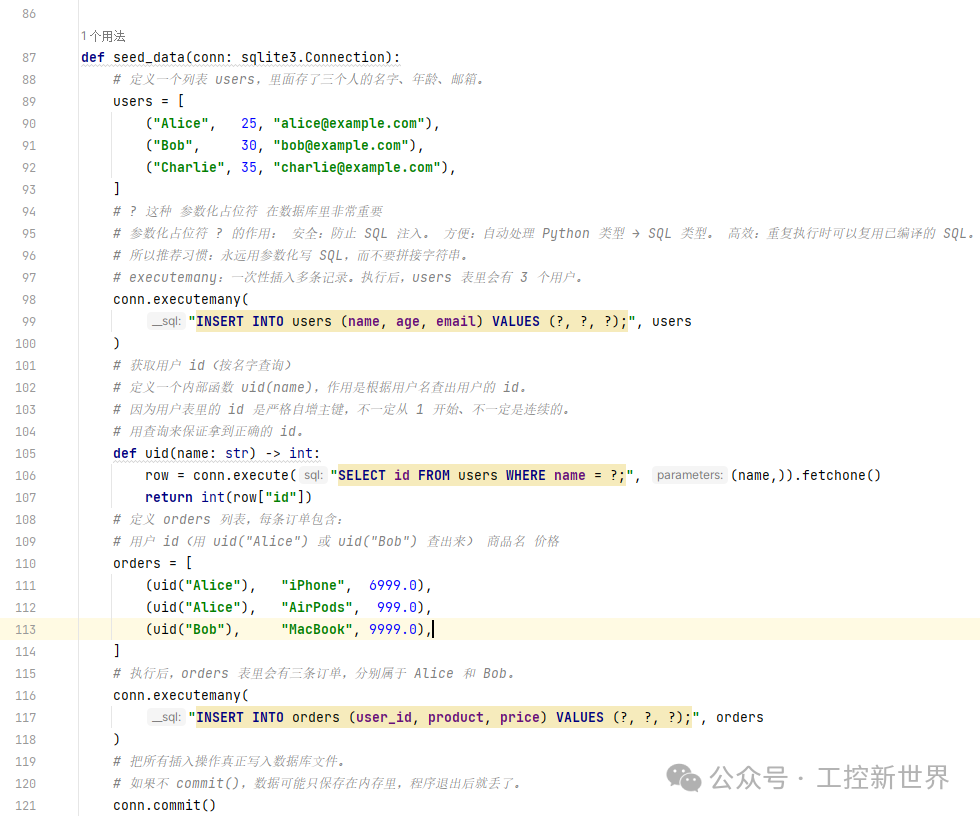
orders 表(订单表)
说明:
user_id = 1 的订单属于 Alice(她买了 iPhone 和 AirPods)。
user_id = 2 的订单属于 Bob(他买了 MacBook)。
Charlie(id=3)暂时没有订单。
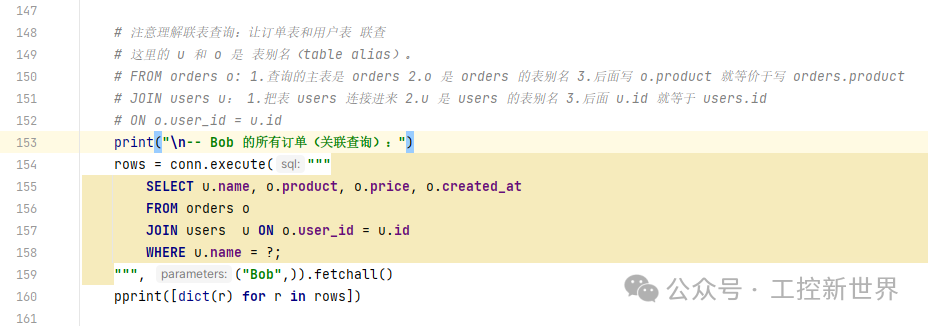
联表查询(谁买了什么)
通过 ON o.user_id = u.id 把订单和用户对上,就能清楚看到:
Alice 买了 iPhone、AirPods
Bob 买了 MacBook
Charlie 暂时没下单,所以没有记录
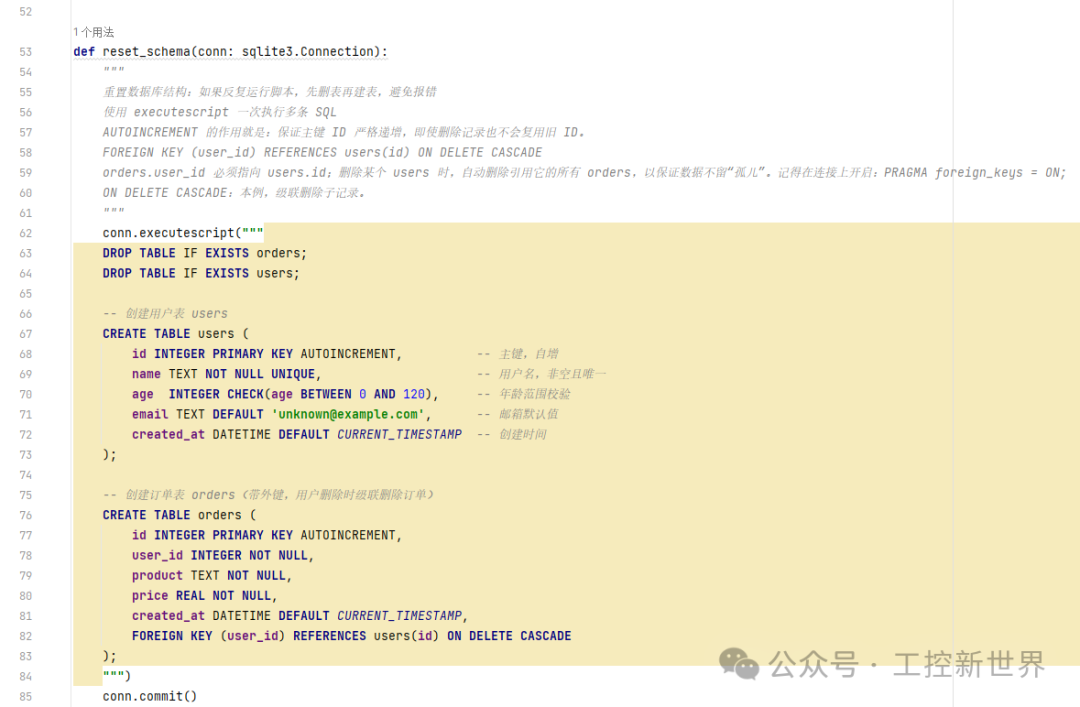
在 SQLite 里,保证 orders.user_id 和 users.id 一一对应,有两层办法:
建表时这样写:

解释:
FOREIGN KEY (user_id):声明 user_id 是外键。
REFERENCES users(id):它必须引用 users 表里的 id。
效果:
不能插入不存在的 user_id。
如果删除了某个用户,ON DELETE CASCADE 会自动删除该用户的订单,避免出现“孤儿订单”。
⚠️ 注意:SQLite 默认 外键是关闭的,要显式打开:
PRAGMA foreign_keys =ON;
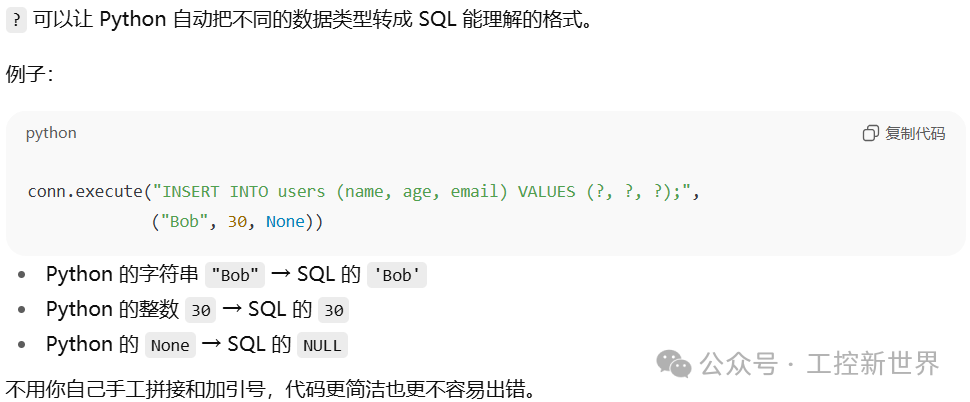
在 Python 里,下单前先检查用户是否存在:
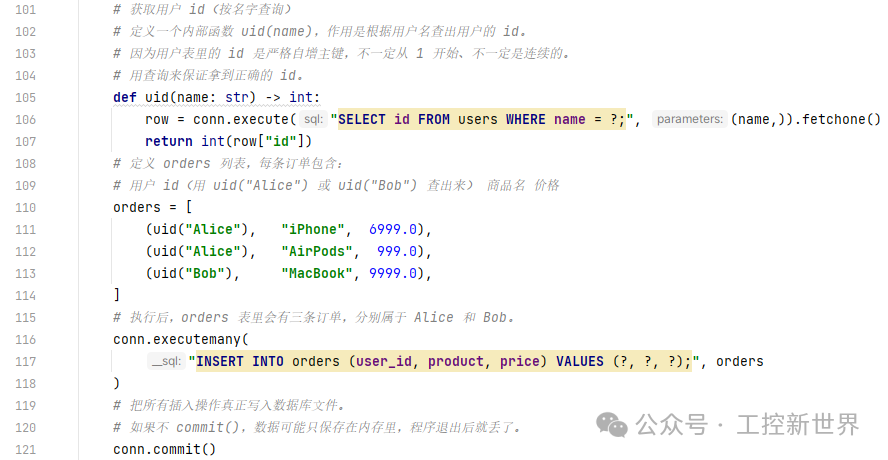
orders表的user_id就是从users表的id来的
函数4:def query_examples(conn: sqlite3.Connection):
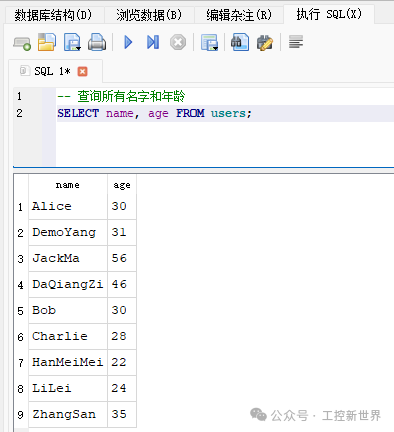
常见查询示例:全表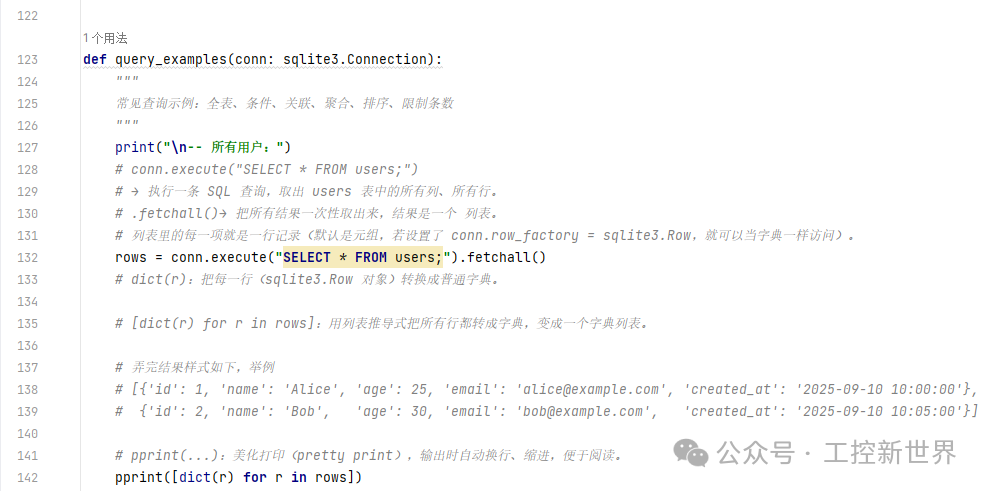


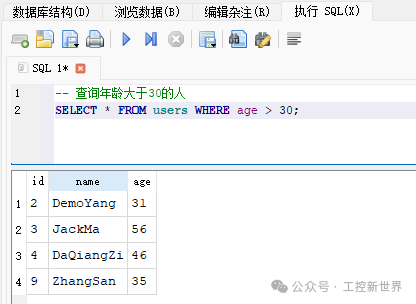
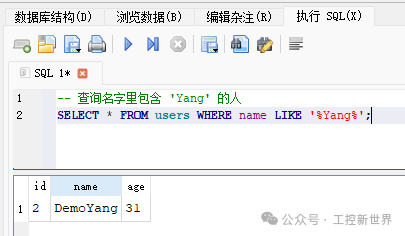
常见查询示例:条件、关联
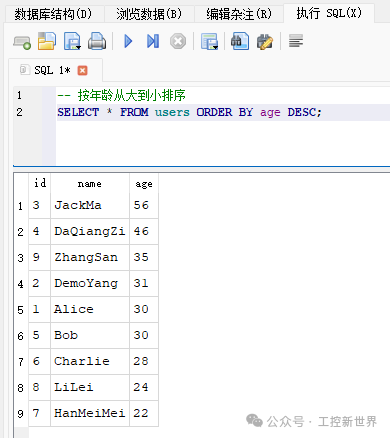
常见查询示例:聚合、排序
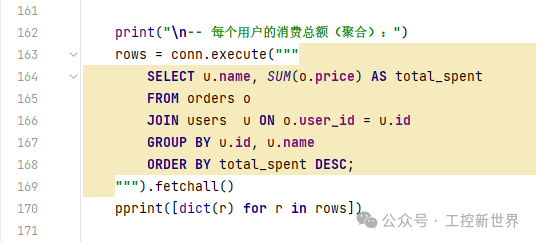
SELECT u.name, SUM(o.price) AS total_spent
选出用户名称 u.name,并对其订单金额 o.price求和。
SUM(...) 是聚合函数,会把同一组(见 GROUP BY)的多行订单加总成一行。
AS total_spent 给这一列起别名“total_spent”,下面 ORDER BY 可以直接用这个别名。
FROM orders o JOIN users u ON o.user_id = u.id
把 订单表 orders(别名 o)和 用户表 users(别名 u)按外键关系联结:o.user_id = u.id。
联结后,每一行订单都带上了对应的用户信息。
GROUP BY u.id, u.name
按 用户进行分组聚合(同一个用户的多条订单归为一组)。
这里同时写 u.id, u.name 是更稳妥的写法:
u.id 唯一标识用户,避免同名不同人的混淆;
u.name 也在 GROUP BY 里,保证 SQL 标准兼容性。
ORDER BY total_spent DESC
按总消费额从高到低排序,谁花得多排在前面。
.fetchall() 与 pprint([dict(r) for r in rows])
取出所有结果行;
-(若设置了 conn.row_factory = sqlite3.Row)把每行转成字典,再美观打印。

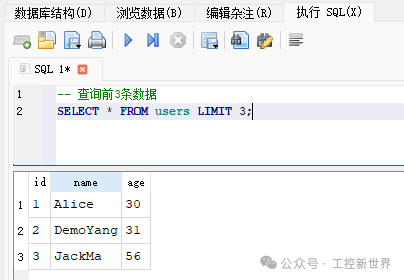
常见查询示例:条件+排序+限制条数
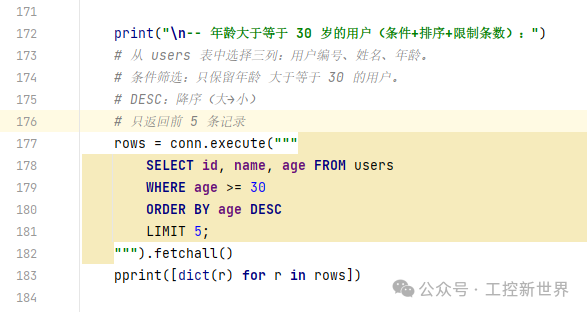
假设 users 表数据:执行查询后结果:
条件:只要 age >= 30 → 剩下 Bob(30)、Charlie(35)
排序:按 age DESC → Charlie(35)、Bob(30)
限制:最多 5 条 → 实际只有 2 条
最终打印:

函数5:def query_examples(conn: sqlite3.Connection):
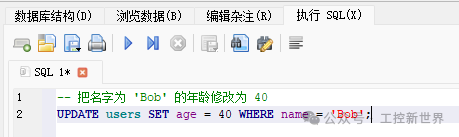
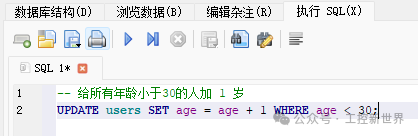
更新示例:单行、多行、表达式更新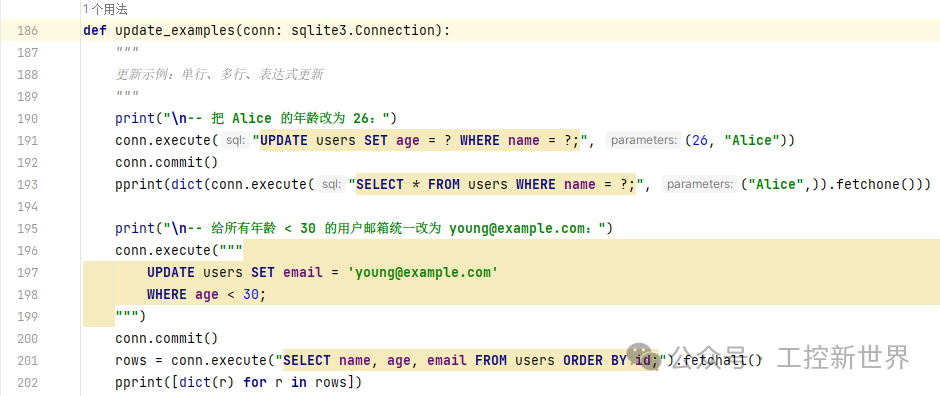
-- 把 Alice 的年龄改为 26:
{'age': 26,
'created_at': '2025-09-11 13:29:22',
'email': 'alice@example.com',
'id': 1,
'name': 'Alice'}
-- 给所有年龄 < 30 的用户邮箱统一改为 young@example.com:
[{'age': 26, 'email': 'young@example.com', 'name': 'Alice'},
{'age': 30, 'email': 'bob@example.com', 'name': 'Bob'},
{'age': 35, 'email': 'charlie@example.com', 'name': 'Charlie'}]
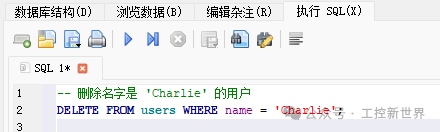
函数6:def delete_examples(conn: sqlite3.Connection):
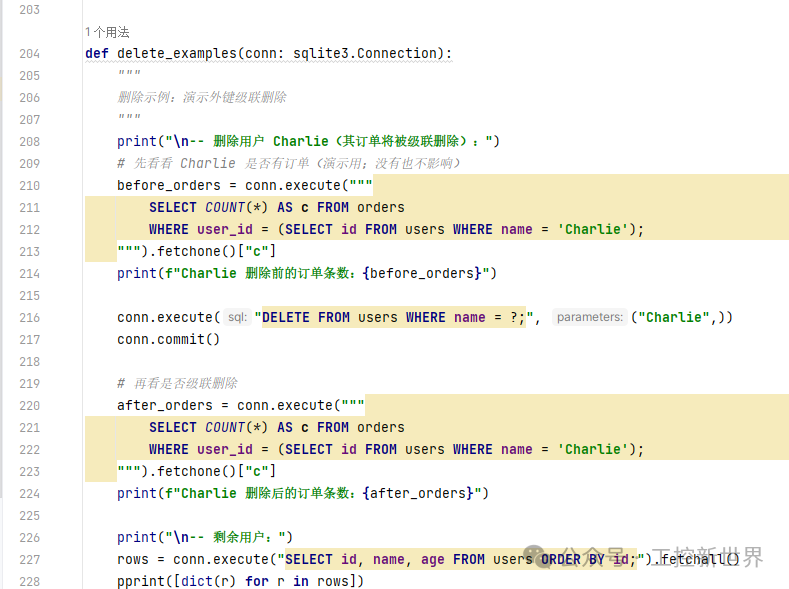
-- 删除用户 Charlie(其订单将被级联删除):
Charlie 删除前的订单条数:0
Charlie 删除后的订单条数:0
-- 剩余用户:
[{'age': 26, 'id': 1, 'name': 'Alice'}, {'age': 30, 'id': 2, 'name': 'Bob'}]
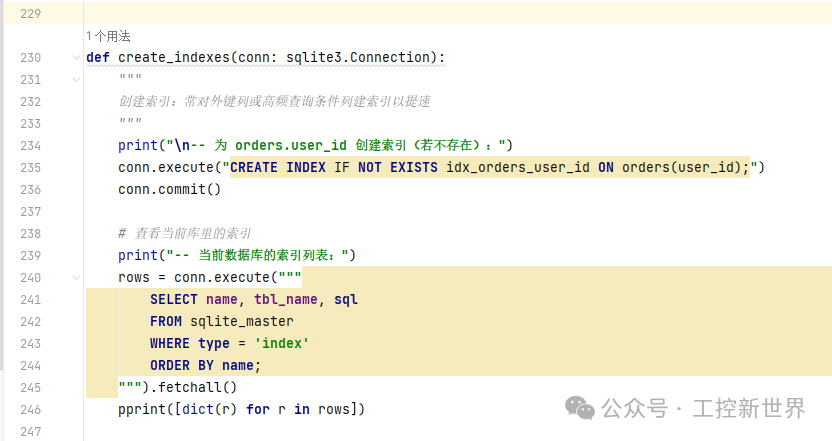
函数7:def create_indexes(conn: sqlite3.Connection):
创建索引
查询现有索引



函数8:def main():

阅读原文:原文链接






 400 186 1886
400 186 1886